
I found Sam Wang’s article this morning interesting for several reasons. He’s saying that Hillary Clinton has a 99% probability of winning tomorrow’s presidential election, and Nate Silver says that it’s kind of ridiculous to posit a number that high. His “now-cast” number, which calculates the probability if the election were held today, is at 66.7%. Wang does a nice, clear job of explaining how they can arrive at such wildly different numbers.
There's a reasonable range of disagreement. But a model showing Clinton at 98% or 99% is not defensible based on the empirical evidence.
— Nate Silver (@NateSilver538) November 5, 2016
Essentially, the two polling analysts have different goals. Silver wants to estimate final margins in all 56 presidential elections tomorrow. There are 56 presidential elections because there are 50 individual states, the District of Columbia, and five congressional districts (in Maine and Nebraska) that will allocate the Electoral College votes. There are also a couple of potentially faithless electors in Washington State who may overrule the people they’re supposed to represent and vote for some third party candidate. Because Silver has so many estimates to make, he has more variables and parameters than Wang, which introduces more uncertainty, which works against making an aggressive prediction in favor of the frontrunner. As Wang says, it’s not that Silver is biased against Clinton. His model would be biased against any frontrunner because it’s biased against certainty.
Wang, on the other hand, has a goal of estimating where people’s time and organization should be best spent. If the presidential election is a slam-dunk then people should spend their time phonebanking for close Senate and House races. He doesn’t care how much Clinton wins by in North Carolina vs. Rhode Island. He doesn’t even really care who wins those states. All he cares about is estimating who will win the overall election. Therefore, he has very few parameters and variables to worry about and he can rely more heavily on the data without introducing a lot of his own uncertainty to the analysis.
Of course, Wang still has to make some assumptions. His primary estimate is to guess how far the actual results will be from the meta-margin (which is defined by how much the polls would have to move in Trump’s direction to create a perfect toss-up). In this case, that number is 2.6%. In the last three elections, the winner over performed the meta-margin in 2004 (1.3%) ,2008 (1.2%) and 2012 (2.3%). The 2000 election was a special case because Al Gore won the popular vote and should have won the Electoral College but did not become the president. He actually underperformed the meta-margin, but probably by less than a point. Basically, the 2000 polls were accurate in predicting the popular vote. The important thing is that, while it’s a pitifully small sample, there is no recent precedent for the mega-margin being off by as much as 2.6%, and the trend has been for the polls to underestimate the size of the win they are predicting (which, in this case, cuts against Trump’s chances).
To make this prediction, Wang increased his sample by looking at historic Senate races from the same period, and he came up with an estimate that the polls are likely to off by only +/- 0.8%. This gives him 99% confidence that Clinton will win. Using different estimates, he comes up with a winning probability of 93% using a slightly different distribution formula, 91% using a +/- 1.5% estimate, and 68% using a +/-5.0% estimate.
In other words, to arrive at Silver’s number, he has to assume that the polls are off by 5% and that there’s a 50% chance that they’re off in Trump’s favor.
Now, Silver’s primary argument against this is that polling errors tend to be highly correlated, so that if the polls are wrong in Clinton’s direction in Ohio they are likely to be similarly off in Pennsylvania and other states.
If you haven't carefully tested how errors are correlated between states, for example, your model will be way overconfident.
— Nate Silver (@NateSilver538) November 5, 2016
Wang doesn’t dispute this, but he argues that his model accounts for it, and not by rating every pollster and adding all the uncertainty of weighting polls’ accuracy.
For each state, my code calculates a median and its standard error, which together give a probability. This is done for each of 56 contests: the 50 states, the District of Columbia, and five Congressional districts that have a special rule. Then a compounding procedure is used to calculate the exact distribution of all possibilities, from 0 to 538 electoral votes, without need for simulation. The median of that is the snapshot of where conditions appear to be today.
Note that in 2008 and 2012, this type of snapshot gave the electoral vote count very accurately – closer than FiveThirtyEight, in fact.
This approach has multiple advantages, not least of which is that it automatically sorts out uncorrelated and correlated changes between states. As the snapshot changes from day to day, unrelated fluctuations between states (such as random sampling error) get averaged out. At the same time, if a change is correlated among states, the whole snapshot moves.
At this point, I’ll let the statisticians arbitrate who is right. If Wang and Silver can’t agree on this point, I am hardly qualified to decide between them.
The final part of Wang’s column that I found interesting was his description of meeting with financial investors.
Let me start by pointing out that FiveThirtyEight and the Princeton Election Consortium have different goals. One site has the goal of being correct in an academic sense, i.e. mulling over many alternatives and discussing them. The other site is driven by monetary and resource considerations. However, which is which? It’s opposite to what you may think.
Several weeks ago I visited a major investment company to talk about election forecasting. Many people there had strong backgrounds in math, computer science, and physics. They were highly engaged in the Princeton Election Consortium’s math and were full of questions. I suddenly realized that we did the same thing: estimate the probability of real-world events, and find ways to beat the “market.”
Silver has been criticized for having a financial incentive in making the election appear closer than it is, but Wang is defending FiveThirtyEight against that charge and saying that he is the one who is seeking money. But he’s also saying that he isn’t distracted by academic questions and is much more results or bottom-line oriented. Just like investors want to use math to help them predict future events and decide where to invest their money, Wang wants to use math to help people decide how to invest their time.
If you think Wang is right, you should be phone banking and knocking doors for downticket candidates because Clinton doesn’t need your help.


I’ve been following this nerd debate closely, a sign of anxiety if ever there was one.
I stopped paying attention a week ago to this, except for what I just read. Do agree with Wang though that downballot is where Dems need the votes.
Downballot is where the fight has been for months. That’s why I’m so pissed about what James Comey and the “Giuliani boys” at the New York FBI office did. They didn’t hurt Hillary; she’s going to win. But they may have hurt the Democrats’ downballot efforts in the House and Senate.
The firings need to commence shortly after the election.
But they may have hurt the Democrats’ down ballot efforts in the House and Senate.
You know what hurts down ballot? Shit candidates. Would Booman be able to tell you who was the Democrat running in his district if he wasn’t a political junkie? Probably not!! Or take Iowa as another example. Obama won it twice yet they keep sending Grassley back by huge margins. What does that tell you?
Some years ago, I was doing field work in Alaska and was talking politics with a colleague from Fairbanks who was assisting in the project. He said he was a Democrat and that he voted for GOP Senator Ted Stevens “every chance he could”. The reason: Stevens was the master of pork-barreling. That was what mattered to my colleague, it turns out.
I have no idea whether what I wrote above is relevant to Iowa and Grassley, but it should at least be considered.
The point of my comment is they never soften someone like Grassley up. I bet any commercials that are ran against him don’t mention how he won’t vote to confirm any Supreme Court Justice nominee Obama, or soon Hillary, will put up. Basically, Grassley is not being made to pay for his obstruction.
Jesus.
Wang was wrong in ’04 and wrong in ’14.
His reasoning is EXACTLY what led to the financial crisis.
Here is why.
The guys on wall street were very smart, but they did not have good data for a time period that included a decline in the Housing market.
And neither does Sam. He has data only from 2000. But if you go further back you find a number of instances where the polling miss was larger than 3 points.
I have data from ’96 and ’92 – it blows the model up.
So basically Sam is full of shit.
Because at the end of the day he doesn’t understand elections and election history.
And I mean that.
The polling averages were OFF by more than three in 1980, 1988, 1992, 1996 and arguably 2000 and 2012.
If you think Clinton has a 99% of winning tomorrow you do not understand politics.
I posted this 2 days ago. This is the effect of a move in polling on Clinton’s expected EV.
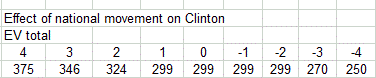
Here is the 5 day polling average in a number of states:
Pennsylvania 2.7
North Carolina 1.5
Florida 1.3
Nevada 1
NH -.2
Ohio -2.5
If polling misses, it will miss in the same direction. THE ERRORS WILL NOT BE RANDOM.
And there is ample evidence such shifts occur.
I happen to think the error will underestimate Clinton’s margin. I think that Clinton will win either Georgia or Arizona.
Because there is systemic risk in counting Hispanics not captured in polling.
But Sam’s position has no defense at all.
No offense, but you don’t understand Wang’s model. He’s not saying the errors will be random. He’s not saying that, at all. You should read his whole article.
I exchange emails with him.
I understand his model very well.
And how does he respond to your points re his model?
There are reasons to expect a shift in either direction. In Hillary’s case, polls may underestimate Latinos who historically have low voting rates. In Trump’s case, there may be some weird variation of the Bradley effect where suburban people don’t want their neighbors to know that they support Trump.
If you respond to a phone poll and tell the caller that you’re going to vote for Trump, how does your neighbor know?
more likely in opposite direction, i.e., wife of white male GOPer takes polling call in hubby’s presence, answers “Trump”, votes Clinton.
I tend to agree with you. Even Wang, in the article, seems to admit if you allow for a slightly greater distribution of possible discrepancies between the meta-margin and the ultimate result, the probability of a Clinton win goes from 99% to about 90%. This seems much more reasonable to me.
Silver’s model, on the other hand, seems to be too wary about using the data it has. In other words, its tails are too big. In the extreme, if you have no confidence at all in your data, you end up with a flat distribution whose central tendency is 50%. So it’s really not so much that his model thinks its a near-tie, so much that it thinks that it doesn’t have enough information, and 50% is the default with no information.
And, of course, there is Silver’s correction of polls for “trend line”, which is perhaps defensible, but certainly has had the effect of making his model very responsive to trends.
At certain points numerical odds of win/loss become meaningless and qualitative rather than quantitative factors are more telling.
FiveThirtyEight – October 30,2016 – The Cubs Have A Smaller Chance Of Winning Than Trump Does
The Cubs winning didn’t improve Trump’s odds.
FiveThirtyEight:
Did Nate not have the right numbers or was it always a toss-up and Nate put a big fat thumb on the scale?
Silver’s numbers now give him a 33% chance of a Trump win. Much too high. We’re near a “Black Swan” factor requirement for Trump to win and therefore, the probability of him winning is much lower than 33%. May not be zero, but it’s damn close to zero.
I think the odds are 10.3%.
Yes, I calculated them…..
But who cares if mathematically the probability is 10% when it doesn’t change the equation that Trump has to carry 1) every state where sometimes he’s led in the polls plus 2) one other state where he’s never led? His odds were always better in NV than MI and WI, but of late he’s been in worse shape than earlier in securing NV.
The open question at this point isn’t whether Trump wins or loses but if he gets more or fewer EC votes than Mitt did. If the former, it will put a big chink in the teabag faction and if the latter they will feel even more empowered but for erroneous reasons.
Hard to determine the validity of Wang’s approach based on this article, and I don’t have time to go any deeper. This phrase from Wang’s article is where I get stuck:
“Then a compounding procedure is used to calculate the exact distribution of all possibilities”
The assumptions used in this procedure regarding correlation between polls are important, and unexplained. Wang is a smart dude and he knows his stuff, so I’m reasonably sure that what he is doing makes sense, but I can’t judge myself based on this incomplete picture.
I can’t think about this debate without harkening back to Tom Tango’s baseball projection system (Marcel) that basically upended — through its simplicity — Silver’s much fancier PECOTA system.
I don’t believe Wang’s 99%, though. Although it would take 100 presidential elections to resolve that one way or another.
The errors in individual senate elections would have to be much larger, I presume, given the less abundant polling.
Wang and Silver are far closer in their projections for the Senate. They’re both calling it basically a toss-up.
Telling a pollster who you support can be just sounding off or letting off steam. It’s easy to to take a risk as it has no consequences. Going to the trouble of actually voting is a more serious decision. You are going to have to live with the result. You may become more risk averse. It also becomes a lonely personal choice – not something to be validated by family and friends.
Sometimes sentiment can change in the final day or two – too late for the polls to capture. Sometimes there can be systematic bias in likely voter screens based on historic patterns. How much do voters really care about emails if the haven’t already committed to one candidate or other. It becomes a rationalisation for a choice made for more complex reasons.
If I were to put money on it, I would tend to favour Hillary winning by a wider than predicted margin, but we are talking probabilities not certainties here, and I live 3000 miles away. I am continually astonished by what passes for public discourse in the US, but then we have had a slightly similar experience with Brexit in the UK just recently.
The lessons learned in WW2 have faded away. Lets hope we are not condemned to to repeat what we have forgotten.
“you should be phone banking and knocking doors for downticket candidates because Clinton doesn’t need your help.”
That was my conclusion back when the conventions were over and that’s where my money went.
I’m not a statistician, but intuitively Silver’s model seems much bouncier than reality and also seems to have more secret sauce than Wang’s, which I would assume at least has the potential to introduce more error. Anyway, I prefer Wang – essentially the same predictive result with far less of the drama and agonizing than Silver’s gyrations.